SQLite3 源码分析-数据格式
前记
这一篇我们将分析一下 SQlite3 的文件格式. 参考链接.
我们需要用到一个网站,可以直观的展示 sqlite3 的格式,带有互动功能.
同时我们还可以使用 sqlite 自带的一个 showdb 的工具来查看 sqlite 的数据库的一些信息.
格式分析
sqlite3 的数据文件被分成了固定大小的页面,然后页面之间通过一个页编号来进行互相引用。
其中页面可以被分为:自由页面(即未被使用的页面),B 树页面,溢出页面。其他页面暂不说明。
数据库头
| 偏移量(字节) | 大小(字节) | 描述 |
|---|---|---|
| 0-15 | 16 | 文件头字符串: “SQLite format 3\000” |
| 16-17 | 2 | 页大小(默认 4096),同时页面大小必须为 2 的次幂数,且范围为 512-32768, 如果是 1 的话,则页面大小为 65536 |
| 18 | 1 | 写入格式版本(1 或 2) |
| 19 | 1 | 读取格式版本(1 或 2) |
| 20 | 1 | 每页末尾保留的字节数(通常为 0) |
| 21 | 1 | 最大的嵌入负载的比例,必须为 64,这个指的是实际存储在页面中的数据的比例 |
| 22 | 1 | 最小的嵌入负载比例,必须为 32,这个指的是实际存储在页面中的数据的比例 |
| 23 | 1 | 叶子页面负载比例,必须为 32 |
| 24 | 4 | 文件修改计数器,即这个数据文件被修改过多少次 |
| 28 | 4 | 数据库大小(以页为单位) |
| 32 | 4 | 第一个自由页面(空闲页面)的编号,我们可以理解为被删除的表所占用的页面 |
| 36 | 4 | 总的自由页面个数 |
| 40 | 4 | schema cookie, 可以理解为用来记录数据库改动的一个参数,在前面我们创建表的时候就要读取这个参数 |
| 44 | 4 | schema 格式类型,目前只有1,2,3,4 这四种,可能随着 sqlite3 的更新还会变化 |
| 48 | 4 | 默认页面缓存大小 |
| 52 | 4 | 在 vacuum 模式下,最大 b 树根页面的页码,否则为 0 |
| 56 | 4 | 数据库文本编码格式,1 表示 UTF-8,2 表示 UTF-16LE, 3 表示 UTF-16BE |
| 60 | 4 | 一个可供用户修改的格式信心,可以使用 PRAGMA schema.user_version = integer ; 来修改 |
| 64 | 4 | 如果不为 0 则表示 incremental-vacuum 模式,否则为 0 |
| 68 | 4 | 应用程序 ID, 一般可用于 file 命令来读取,当然也可以使用 PRAGMA 命令来修改适用于用户自己的文件类型 |
| 72 | 20 | 用于扩展,必须为 0 |
| 92 | 4 | 版本有效数字 |
| 96 | 4 | 最新修改数据文件的SQLite版本号 |
我们可以在如下的网站中查看具体的信息: 
我们也可以使用 showdb 命令来查看数据库头信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
./showdb ./test.db dbheader
Pagesize: 4096
Available pages: 1..2
000: 53 51 4c 69 74 65 20 66 6f 72 6d 61 74 20 33 00 SQLite format 3.
010: 10 00 01 01 00 40 20 20 00 00 00 01 00 00 00 02 .....@ ........
014: 00 0 Reserved space at end of page
018: 00 00 00 01 1 File change counter
01c: 00 00 00 02 2 Size of database in pages
020: 00 00 00 00 0 Page number of first freelist page
024: 00 00 00 00 0 Number of freelist pages
028: 00 00 00 01 1 Schema cookie
02c: 00 00 00 04 4 Schema format version
030: 00 00 00 00 0 Default page cache size
034: 00 00 00 00 0 Largest auto-vac root page
038: 00 00 00 01 1 Text encoding
03c: 00 00 00 00 0 User version
040: 00 00 00 00 0 Incremental-vacuum mode
044: 00 00 00 00 0 Application ID
048: 00 00 00 00 0 meta[8]
04c: 00 00 00 00 0 meta[9]
050: 00 00 00 00 0 meta[10]
054: 00 00 00 00 0 meta[11]
058: 00 00 00 00 0 meta[12]
05c: 00 00 00 01 1 Change counter for version number
060: 00 2e 63 00 3040000 SQLite version number
空闲页面
数据库文件可能包含一个或多个未使用的页面,例如,当信息从数据库删除时,就是出现未使用的页面.未使用的页面存储在空闲列表中,当需要使用额外页面的 时候,这些页面将重新被使用.
第一个空闲页面的编号存储在数据库头文件偏移量为 32 的地方,总的空闲页面数量存储在偏移量为 36 的这个地方.
空闲页面的方式以链表的形式进行组织.每个空闲页面包含 0 个或多个空闲页面的页码.
空闲页面由一个四字节大端序整数数组组成,其中第一个 4 字节是下一个空闲页面的页面,如果这是最后一个空闲页面,则数组第一个值为 0, 第二个 4 字节是当前空闲页面记录的空闲页面的个数,后续的 4 字节数也是空闲页面的页码.
我们可以查看当前网站来分析空闲页面的组织方式: 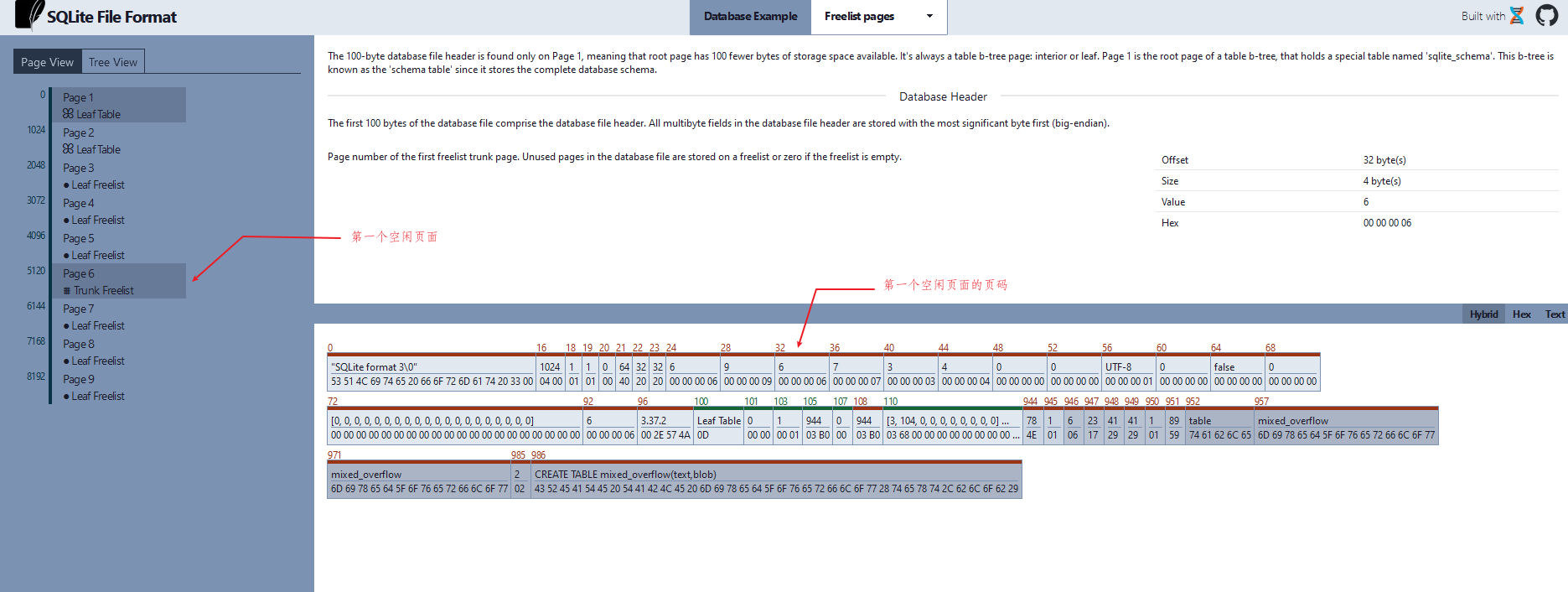
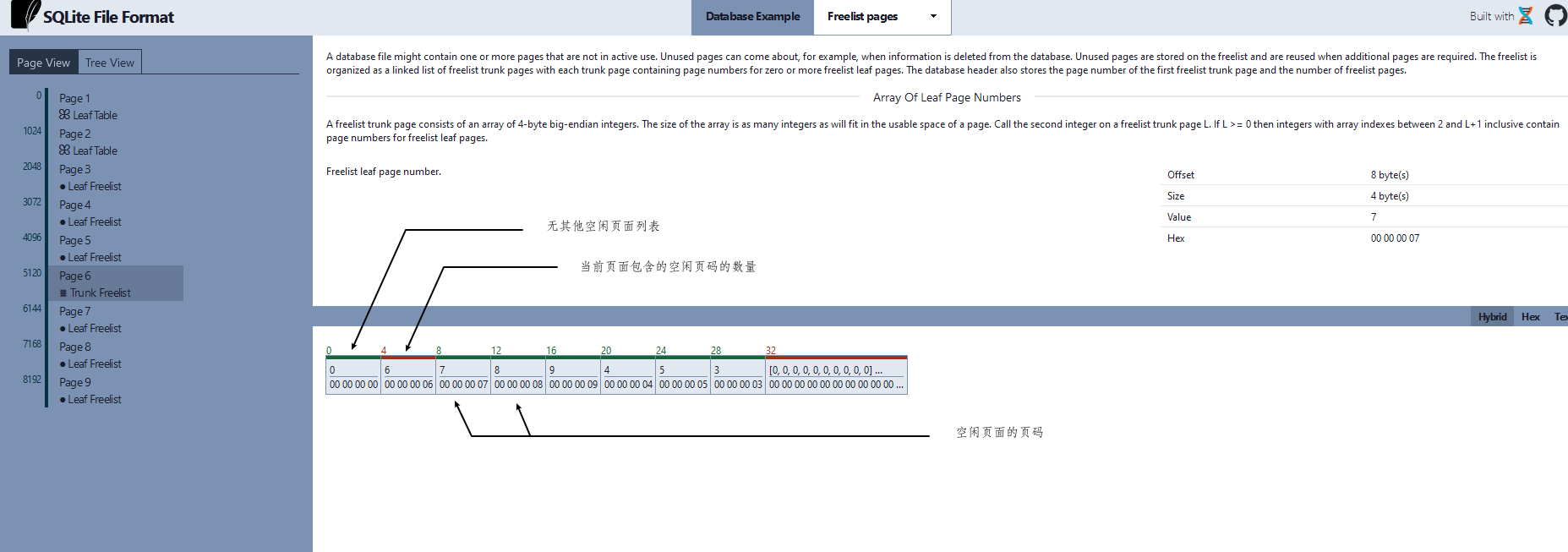
同时我们也可以使用 showdb 来查看空闲页面的信息,我们可以使用如下语句来生成多个空闲页面
1
2
3
4
5
6
7
8
9
10
11
create table test(id int);
WITH RECURSIVE
numbers(value) AS (
SELECT 1
UNION ALL
SELECT value + 1 FROM numbers
LIMIT 1000
)
INSERT INTO test (id)
SELECT value FROM numbers;
drop table test;
- 查看第一个空闲页面的页码以及数量
1
2
3
4
5
6
7
8
9
./showdb ./test.db dbheader
Pagesize: 4096
Available pages: 1..5
000: 53 51 4c 69 74 65 20 66 6f 72 6d 61 74 20 33 00 SQLite format 3.
010: 10 00 01 01 00 40 20 20 00 00 00 03 00 00 00 05 .....@ ........
020: 00 00 00 03 00 00 00 04 00 00 00 02 00 00 00 04 ................
030: 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00 00 ................
050: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 03 ................
060: 00 2e 63 00 00 ..c..
我们可以看到偏移量为 32(0x20) 处的数字为 3, 偏移量为 36(0x24) 的数字为 4.说明第一个空闲页面的编码为 3, 总的空闲页面个数为 4.
2.查看空闲页面的编码
1
2
3
4
5
6
7
./showdb ./test.db 3td
Pagesize: 4096
Available pages: 1..5
Decode of freelist trunk page 3:
000: 00 00 00 00 0 Next freelist trunk page
004: 00 00 00 03 3 Number of entries on this page
[0] 4 [1] 5 [2] 2
我们可以看到在页面 3 上,下一个空闲页码为 0 ,说明没有其他空闲页面,当前页面上包含3 个空闲页面的页码,他们分别为 4,5,2.
所以总共的空闲页面为3,4,5,2
flowchart TB
A(["Page 3"])
B(["Page 4"])
C(["Page 5"])
D(["Page 2"])
A --> B
A --> C
A --> D
B 树页面
关于 B 树的组织形式,我们可以查看这个链接 来进行插入和删除操作 对B 树有一个直观的了解,在内部节点中只有用于查找的关键字实际的数据存储在叶子节点中.
B 树页面按以下顺序划分为若干区域:
- 100 个字节的数据库头信息,这个只有在第一个页面才有
- 如果为叶子页面由 8 个字节组成的页面头信息,如果为内部页面,则由 12 个字节组成的页面信息
- 单元指针数组,指向数据库存储的具体信息
- 未分配空间
- 数据库具体存储的信息
- 保留区域
保留区域是每页末尾未使用的空间,扩展应用程序可以用于保存每页信息,保留区域的大小由数据库头信息偏移处 20 的字节决定,一般为 0.
页面头信息如下
| 偏移量(字节) | 大小(字节) | 描述 |
|---|---|---|
| 0 | 1 | 用于描述页面的类型,0x02 表示索引内部页面,0x05 表示表内部页面,0x0a 表示索引叶子页面,0x0d 表示表叶子页面 |
| 1 | 2 | 表示当前页面第一个可用块的位置,如果没有可用块,则为 0 |
| 3 | 2 | 表示当前页面包含多少个内容单元 |
| 5 | 2 | 表示当前页面内容区域的开始位置,如果是 0 的话,则表示为 65536 |
| 7 | 1 | 单元格内容区域内的碎片空闲字节数 |
| 8 | 4 | 当前内部页面最右边指针指向的页码 |
如果一个页面不包含单元格(一般出现在一个数据表的根页面且没有任何数据),那么单元格内容区域的偏移量就等于页面大小减去保留空间的字节数.如果数据库使用的页面大小为 65536,且保留字节为 0,那么这个单元格内容区域的偏移量就是 65536,然而这个放不进 2 个字节内,所以用 0 来表示,这个我们后边会进行说明.
B 树页面上的可用空间总量由未分配区域的大小、所有可用块的总大小以及碎片可用字节数组成。SQLite可能会不时重组 B 树页面,以消除可用块或碎片字节,将所有未使用的字节都包含在未分配空间区域中,并将所有单元格紧密地打包在页面末尾。这被称为”碎片整理” B 树页面.
我们在 B 树的页面上存储来内容单元格,那么这些内容单元格是以什么样的形式存储到页面上的呢?
SQLite3 中存储的数据很多都是可变长度,可以有效减少数据的长度,和哈夫曼编码有点类似.下文中出现的
varint均为此.
数据表叶子页面(0X0D)
- 有效内容的总字节数(varint),包括溢出的内容(比如字符串太长来,一个页面很难放得下,就放到溢出页面中)
- 一个整数键(varint),可以理解为
rowid,即行号 - 有效内容,这里不包括溢出的内容
- 溢出页面列表第一页的 4 字节大端整数页码,如果所有的有效内容都在这个 B 树页面上,则省略
数据表内部页面(0X05)
- 一个 4 字节大端页码,即左子页面指针
- 一个 variant, 用于 B 树的键值
索引叶子页面(0x0A)
- 索引键的总字节数(varint),包括任何溢出
- 有效内容的初始部分,不会溢出到下一页的部分
- 溢出页面列表第一页 4 字节大端整数页面,如果所有的有效内容都在这个 B 树页面上,则省略
- 溢出页面列表第一页的4字节大端整数页码——如果所有有效载荷都位于 B 树页面上,则省略
索引内部页面(0x02)
- 4 字节大端页面,左子页面指针
- 索引键的有效内容字节数(varint), 包括任何溢出
- 有效内容的初始部分,不会溢出到下一页
- 溢出页面列表第一页的4字节大端整数页码——如果所有有效载荷都位于 B 树页面上,则省略
接下来,我们来一次看一下这四种页面:
数据表叶子页面
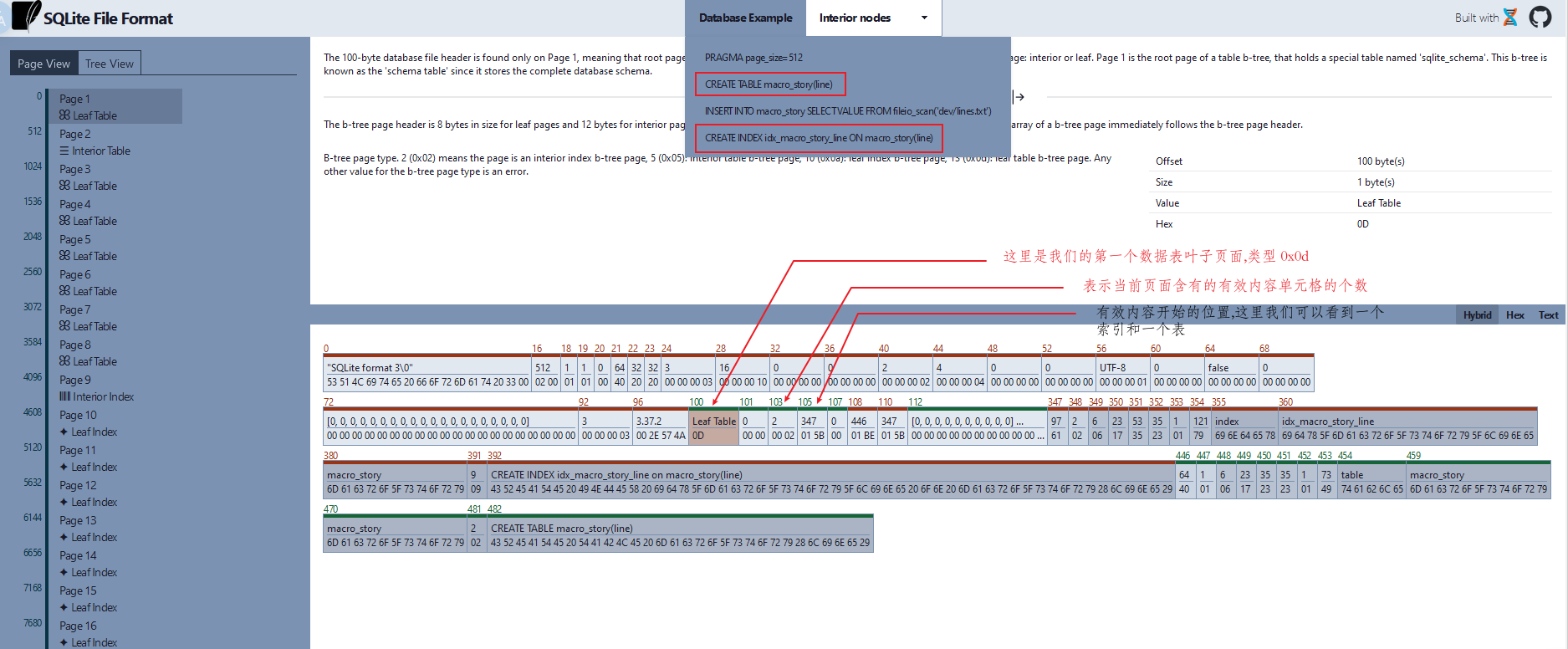 表的叶子页面类型为 0x0D,当数据库中数据表不多时,我们就可以看数据库的第一个页面,因为一个页面就可以存储所有表的元信息. 这个图中,我们可以看出页面类型为数据表叶子页面.包含的有效内容单元格个数为2,有效内容开始的偏移量为 347.创建了一个表和一个索引. 同时位于 108 和 110 两个位置的数值,正好是每个内容单元格的起始位置.
表的叶子页面类型为 0x0D,当数据库中数据表不多时,我们就可以看数据库的第一个页面,因为一个页面就可以存储所有表的元信息. 这个图中,我们可以看出页面类型为数据表叶子页面.包含的有效内容单元格个数为2,有效内容开始的偏移量为 347.创建了一个表和一个索引. 同时位于 108 和 110 两个位置的数值,正好是每个内容单元格的起始位置.
数据表内部页面
从上面的图中,我们可以看到偏移量为 481 字节处的值为 2,这表明数据表 macro_story 数据表的根页面页码为 2.然后我们来看一下 0x02 页面. 
从这个图中我们可以看出,页面类型为数据表内部页面,接着就是有效内容单元个数,最右页面的页码,然后就是有效内容了,有效内容就是一个指向子页面的页码和一个用于 B 树排序的键值.那些指针页码可以直接点击跳转到指向的页面.
溢出页面
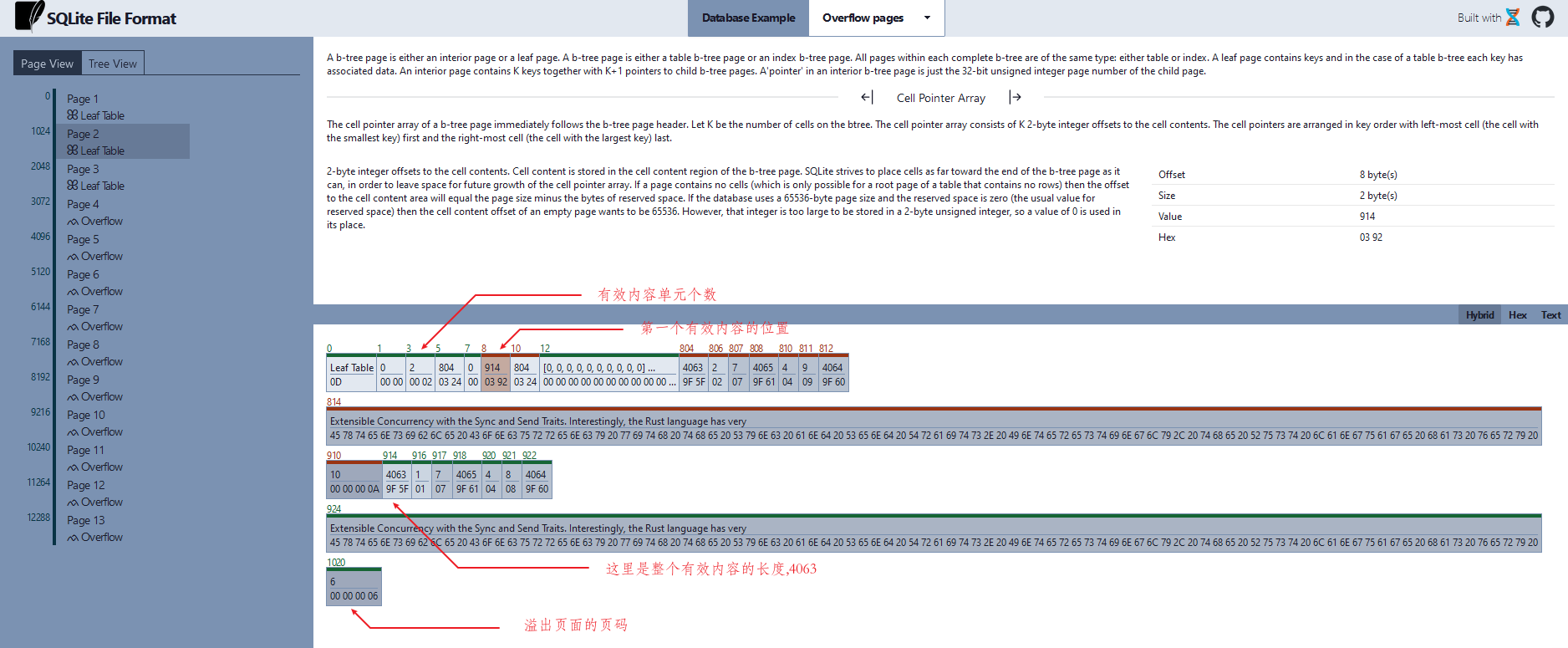
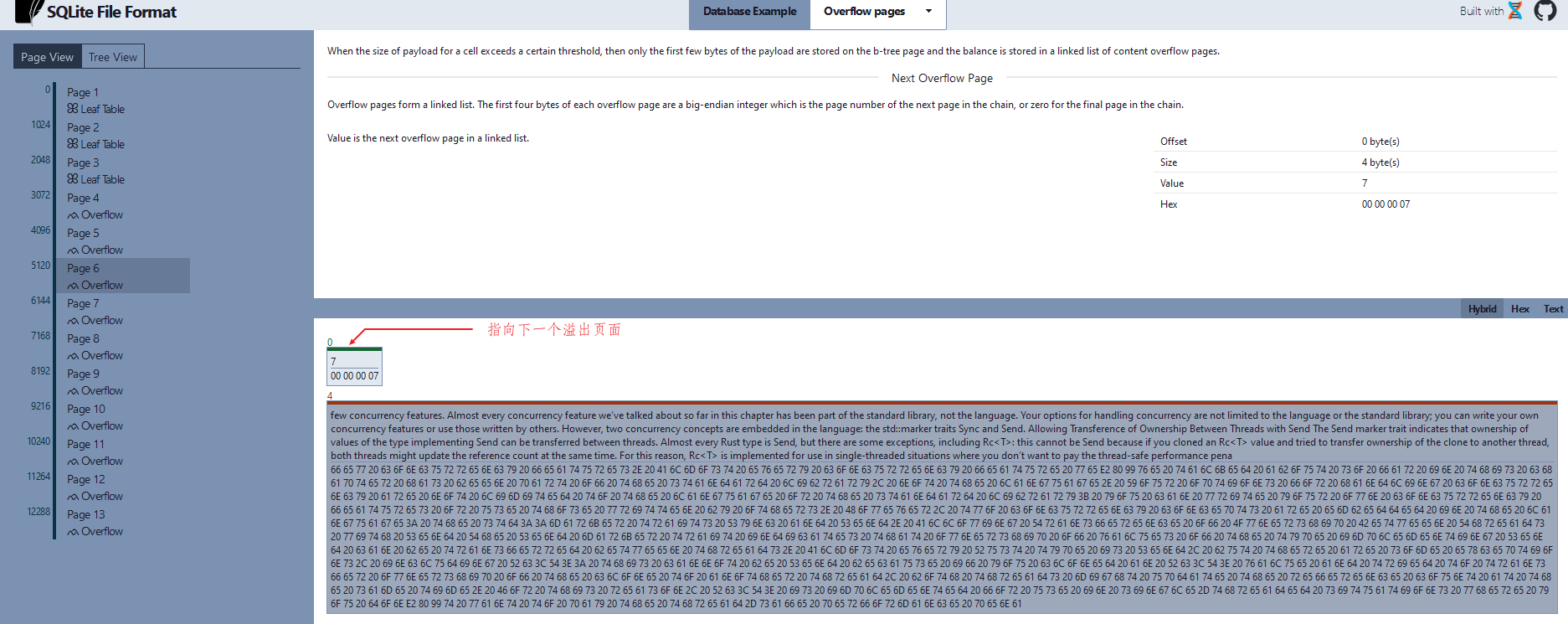
从上面的两个图中我们可以看出整个内容的长度为 4063,没有放到一个页面中,所以我们这里使用了溢出页面,下一个溢出页面为 6.
页面 6 有指向了溢出页面 7 ,形成来一个链表.
Varint 数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
/*
** Convert the var-int format into i64. Return the number of bytes
** in the var-int. Write the var-int value into *pVal.
*/
static int decodeVarint(const unsigned char *z, i64 *pVal){
i64 v = 0;
int i;
for(i=0; i<8; i++){
v = (v<<7) + (z[i]&0x7f);
if( (z[i]&0x80)==0 ){ *pVal = v; return i+1; }
}
v = (v<<8) + (z[i]&0xff);
*pVal = v;
return 9;
}
/*
** Describe cell content.
*/
static i64 describeContent(
unsigned char *a, /* Cell content */
i64 nLocal, /* Bytes in a[] */
char *zDesc /* Write description here */
){
i64 nDesc = 0;
int n, j;
i64 i, x, v;
const unsigned char *pData;
const unsigned char *pLimit;
char sep = ' ';
pLimit = &a[nLocal];
n = decodeVarint(a, &x);
pData = &a[x];
a += n;
i = x - n;
while( i>0 && pData<=pLimit ){
n = decodeVarint(a, &x);
a += n;
i -= n;
nLocal -= n;
zDesc[0] = sep;
sep = ',';
nDesc++;
zDesc++;
if( x==0 ){
sprintf(zDesc, "*"); /* NULL is a "*" */
}else if( x>=1 && x<=6 ){
v = (signed char)pData[0];
pData++;
switch( x ){
case 6: v = (v<<16) + (pData[0]<<8) + pData[1]; pData += 2;
case 5: v = (v<<16) + (pData[0]<<8) + pData[1]; pData += 2;
case 4: v = (v<<8) + pData[0]; pData++;
case 3: v = (v<<8) + pData[0]; pData++;
case 2: v = (v<<8) + pData[0]; pData++;
}
sprintf(zDesc, "%lld", v);
}else if( x==7 ){
sprintf(zDesc, "real");
pData += 8;
}else if( x==8 ){
sprintf(zDesc, "0");
}else if( x==9 ){
sprintf(zDesc, "1");
}else if( x>=12 ){
i64 size = (x-12)/2;
if( (x&1)==0 ){
sprintf(zDesc, "blob(%lld)", size);
}else{
sprintf(zDesc, "txt(%lld)", size);
}
pData += size;
}
j = (int)strlen(zDesc);
zDesc += j;
nDesc += j;
}
return nDesc;
}
由上面的代码,我们可以看出 varint 是一个变长的类型.对于一个字节,如果在最高位为 1,则表示后续还有字节,如果为 0 则表示没有字节.且最大长度为 9 个字节.同时这个字节里包含量长度和类型信息,我们举例说明:
1
2
3
PRAGMA page_size=512;
create table test(id int, rate float, name text);
insert into test(id,rate,name) values(1000,1.66,"Hello World");
这里我们设置页面大小为 512 方便使用 showdb 进行查看.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
./showdb ./test.db 2..2
Pagesize: 512
Available pages: 1..2
Page 2: (offsets 0x200..0x3ff)
000: 0d 00 00 00 01 01 e5 00 01 e5 00 00 00 00 00 00 ................
1e0: 00 00 00 00 00 19 01 04 02 07 23 03 e8 3f fa 8f ..........#..?..
1f0: 5c 28 f5 c2 8f 48 65 6c 6c 6f 20 57 6f 72 6c 64 \(...Hello World
./showdb ./test.db 2bc
Pagesize: 512
Available pages: 1..2
Header on btree page 2:
000: 0d 13 table leaf
001: 00 00 0 Offset to first freeblock
003: 00 01 1 Number of cells on this page
005: 01 e5 485 Offset to cell content area
007: 00 0 Fragmented byte count
key: lx=left-child n=payload-size r=rowid
1e5: cell[0] n: 25 r: 1 1000,real,txt(11)
这里我们可以看到在 0x1e5 的位置是有效内容的其实位置, 0x19 是有效内容的长度,二进制为 0001_1001 ,最高位是 0 ,所以没有后续字节. 0x01 表示 rowid, 剩余的为有效内容.
0x04 表示 record header 一共四个字节.包括 0x04 这个长度.
0x02 表示一个大端的 2 字节的整数
0x07 表示一个大端IEEE 754-2008 8 字节浮点数
0x23 表示一个文本类型,文本的长度为 (0x23-13)/2 = 11, 后面的数据就是我们实际存入的数据.
0x03 « 8 + 0xe8 = 1000
3FFA8F5C28F5C28F 是 1.66 的十六进制表示
剩余内容为 Hello World 的十六进制表示.
后记
终于理解了 sqlite3 的数据格式了.😎,不过对于溢出页面的相关计算还是不懂.